
实现自动驾驶的难点有哪些?
从车道保持到高阶自动驾驶功能,都需要车辆所处的静态、动态环境的准确信息。通过传感器数据融合,可以获得有关其他交通参与者的动态信息、静态环境以及道路和交通规则的信息。俗话说“单丝不成线,独木不成林”。面对如此复杂的自动驾驶系统,最好的办法自然是博采众长,多传感器融合咯。
01、False Positive & False Negative
这是做多传感器融合之前必须了解的一个概念。统计学上的名字叫第一类错误和第二类错误。当然,这么专业的名字经常搞得人云里雾里。实际上,除了FP和FN之外,还有TP和TN,组成了如下图所示的四角关系。
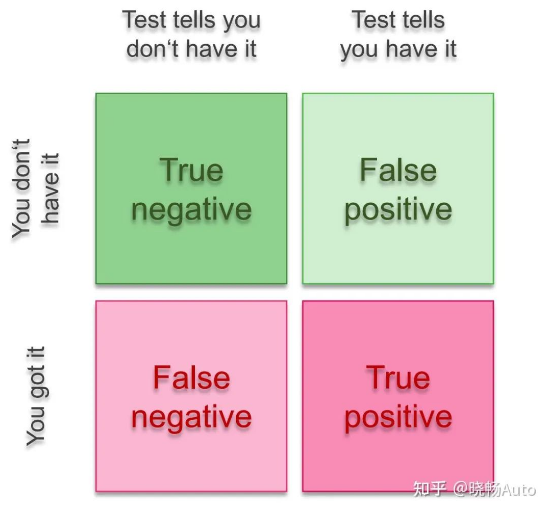
医学上经常会用这个术语来表述检测结果和实际结果的差别,经典的例子就是你有没有得肿瘤导致你心情大起大落的故事。在自动驾驶感知任务中,FP和FN常被描述成如下场景:
FP:传感器探测到了目标,但实际上没有这个目标。这样的目标又被称作ghost。
FN:传感器没有探测到目标,但实际上有这个目标。这样的情况被称为漏检。
对于双目摄像头而言,它能感知深度,这原本是个很不错的能力。但是当双目摄像头遇上有强光反射的光滑地面时,强光导致的图像局部饱和会让摄像头的深度测量出现偏差,而误以为地上有一个洞。但我们都知道实际上地面上并没有洞,那这就是一个false positive。
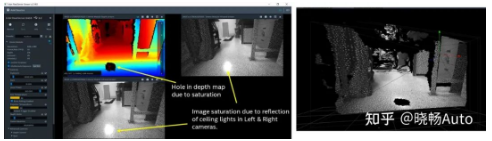
明亮的地面反射导致摄像头探测到了洞
而这样的偏差会导致汽车在行驶过程中误以为前方不能通行,需要绕行避让或直接刹停,从而产生让人觉得莫名其妙的“幽灵刹车”。但是面对同样的场景,毫米波雷达就不会探测出一个洞来,因为它通过自身发出的电磁波来感知周围环境而不受光线强弱的影响。这时候采用传感器融合,就能够避免这样的问题。
02、目标检测
了解了多传感器融合的必要性之后,我们来看看多传感器融合的细分任务。首要的任务便是目标检测。对于自动驾驶汽车来说,周围环境中最多的、出现频率最高的自然是其他汽车。而目标检测就是要用一个个小框把他们框起来,从而与周围环境区别开来。这样的框我们就称为bounding box。Bounding box可以分成二维和三维的,分别对应目标检测里的二维目标检测及三维目标检测方法。2D bounding box,顾名思义每一个框子都是平面的。好处在于简单快捷的把一帧图像或是点云里的目标标识出来。

但是同时缺点也是显而易见的。第一,由于框子也是二维的是一个平面,我没法知道这里车的长或者宽;第二,目标的行驶方向也无法体现出来。这两点在车辆进行ACC、AEB纵向功能时可能还不明显,但一旦涉及到车辆横向控制,需要变道时,缺少这些信息则是致命的。于是,三维的目标检测应运而生,并逐渐成为目标检测的主流。同时,我们也会把目标分类合并在一起做掉,这可以通过神经网络的多头设计来完成。因此你会看到目标的框上有一个分类以及分类的置信度。不同类别的目标有不同的几何外形,这样也能方便设计不同大小的框子对应不同类别的目标。
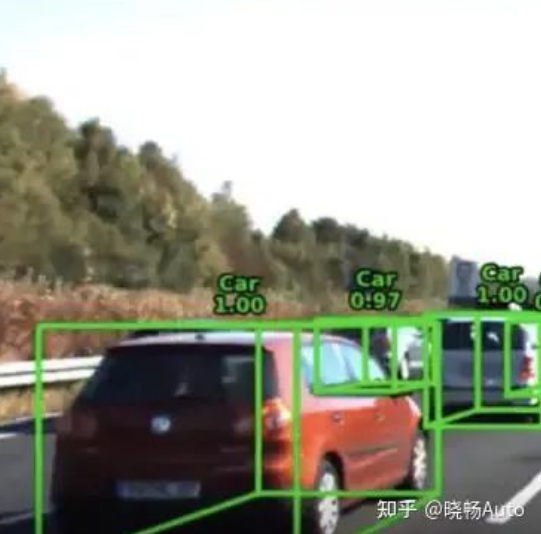
不过3维框也有其局限,我们都知道车辆的外表并非一个完美的长方体,而都用长方体框出就忽略掉了很多外观上的细节。而这些细节在近距离跟车、加塞变道时会变得特别有用。
03、目标追踪
目标检测还只是针对单帧的画面和数据,但是实际上我们的运动场景是连续的,我们不能只简简单单在一张或几张图片上成功检测到物体就足够,还需要跨帧地确保这些目标联系起来,即知道这些目标是同一个目标在不同时间戳的表示。这就是目标追踪。目标追踪的常用结构就是依据我们之前讲过的卡尔曼滤波结合目标关联算法。先预测,再关联,后更新。九字箴言。对于不同的目标我们会建立不同的数学模型,例如针对静止目标,由于速度始终为0不会变化,我们就会用恒定速度(constant velocity)模型来建立运动学模型;而针对运动的目标,尤其是车辆这种还带有旋转、拐弯的一般会用匀速圆周运动模型(constant turn rate and velocity)。不同的模型意味着不同的预测结果。
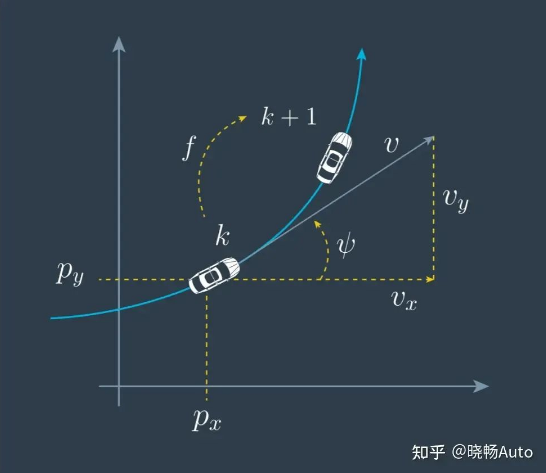
而有了预测值之后,你就能大约猜测出下一个周期目标应该会出现在图上的什么位置,从而去那个范围搜寻对应的像素点或者点云,把合适的点与预测的目标位置关联上。关联上后你就获得了这个时刻的测量值,你就可以用测量去校正之前的预测,从而获得精确的目标位置。这样,循环往复,周而复始,你就成功地tracking上了这个目标。在实际自动驾驶项目中,丢目标和目标跳变是一个很严重的问题。这里的“丢目标”指的就是目标追踪失败,传感器没能跟上目标实际的运动轨迹;“目标跳变”指的就是目标追踪丢失后又重新跟上。由于这两者都会导致目标ID变化而导致功能退出,因此都是需要在目标融合时极力避免的。
04、总结
这里主要介绍了传感器融合(SF)对目标方面的几类任务,除目标之外,传感器融合还能做很多其他对环境建模的任务,例如道路特征的描述、占用栅格地图以及可通行区域表示等等。

评论 (0人参与)
最新评论